Ok, I'm still on robots; artificial life, this issue...
This isn't the only thing I will ever put out, but I've just seen something that is so cool I had to pass it on. {ed: actually, I've spent two months writing this and the Javascript simulation at the end} There are several real problems in robotic systems that relate to complexity and cost. One of the biggest is the need for position, speed, and direction sensing on each and every actuator. The idea of building a simple robot base (much less a complex system like a multiple degree arm) without an encoder on every axis pretty much moves a design into the "toy" category. Anyone who tries to build an "open loop" system, where the actuators effect is not measured and fed back into the system, learns that even small errors introduced by "minor" variations are multiplicative rather then additive. Things may start right on, but before long, they stray and then go completely wacky. Something has to close the loop. And how else can you do that but with an encoder of some type at each and every joint?
The same way we do...with vision.
Now, we also have the ability to sense the positions of our joints without looking at them, and we need it because our eyes are not designed to see all of our body, all of the time. In fact, we have at least 3 ways to know where we are: vision, balance organs, and this internal sense of position called proprioception by modern neuroscientists. Loosing it can be devastating, as related in the case of Christina, "The disembodied lady" which is chapter 3 in the excellent book "The Man Who Mistook his Wife for a Hat by Oliver Sacks. As Christina described it herself: "It's like the body's blind. My body can't "see" itself; it's lost its eyes, right? So *I* have to watch it - be its eyes." And, in fact, she was able to function (with care) by simply... well... watching what she was doing.
Loosening either of the other two systems, especially vision is much worse. Think about what you do when you are catching a ball: First, your eyes are tracking the ball; your eye is moving so that the fovea, the hi-resolution sensor at the very center, is always pointed exactly at the object of interest. This is called "Smooth-pursuit" stabilization. Now, relative to your eye, the ball is NOT moving. What you actually see is the ball in the center of the picture and everything else flying by. Now, you move your hand to catch the ball. If the ball is big this probably doesn't matter, but when you need precision, your eye guides your hand to the target at the center. It starts as the hand becomes visible from the corner of your eye; up to that point you need proprioception. But from then on, you don't need that anymore. The eye will guide the arm to move the hand very nicely, very accurately, and very quickly to the target at the center. Christina even learned to type at her home computer, and quite well in fact... as long as she was looking at her hands.
 And
how does all of this relate to 'bots? Well, back in the 1960's and 70's there
was a great deal of research aimed at learning how mother nature does things and
applying that to machines. It was called cybernetics,
and it seems to have changed its meaning a bit or fallen out of favor in the
USA, but at the time, it was the rage. There was a lot of research (sponsored
mostly by DARPA) into the ability of things like frogs to catch flies...
hummm...wonder why the military was interested in flies? And the nervous system
behind the frogs eye was studied to the point that its operation could, to a
degree, be duplicated. I remember reading this stuff as a kid and marveling at
how clever the design of this fly catching "machine" was.
And
how does all of this relate to 'bots? Well, back in the 1960's and 70's there
was a great deal of research aimed at learning how mother nature does things and
applying that to machines. It was called cybernetics,
and it seems to have changed its meaning a bit or fallen out of favor in the
USA, but at the time, it was the rage. There was a lot of research (sponsored
mostly by DARPA) into the ability of things like frogs to catch flies...
hummm...wonder why the military was interested in flies? And the nervous system
behind the frogs eye was studied to the point that its operation could, to a
degree, be duplicated. I remember reading this stuff as a kid and marveling at
how clever the design of this fly catching "machine" was.
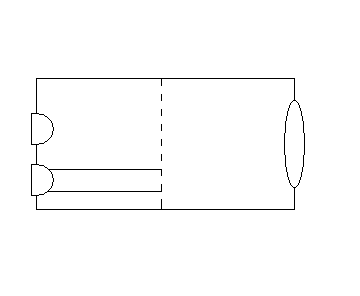
As part of my growing collection of very early Byte magazines, I found an article in the March 1979 issue by Andrew Filo of Akron OH titled "Designing a Robot from Nature" in which the author shows how the vision system of a frog can be adapted to robotics. He describes a "NetConvexity Detector" based on part of the nerves behind the retina of the frogs eye. This construct can detect (very roughly) the size, position, speed, and direction of an object... and it uses only TWO photocells! Now, it is very limited in accuracy, reliability, and versatility but it was able to guide an open loop robotic arm to manipulate objects. Here's how it works.
One of the photocells is in a small, white, chamber behind a mask of small holes of the size of object you want to detect. On the other side of the mask is another chamber with black walls and on the other side of that space is a lens with a focal point at the mask. So, light from the object shines onto the mask, and as it moves by, the mask allows that light through or blocks it so that the photocell receives a set of pulses as the object moves. An object bigger than the holes in the mask allows light through more than one hole so there is never a time when the light is blocked and so, no pulses. This part gives us the amount of movement.
| 11110 | v | top to bottom |
| 10 | ./ | top right to bottom left |
| 1011 | < | right to left |
| 011 | '\ | bottom right to top left |
| 01111 | ^ | bottom to top |
| 01 | /' | bottom left to top right |
| 1101 | > | left to right |
| 110 | \, | top left to bottom right |
One hole in the mask; off center, is connected to the second photocell only. In the original design, it was important that the object pass over that specific hole at least once during its journey over the mask. This requirement can be eliminated with the use of a second mask as we shall see later. This special hole is marked with a @ in the figures below. These figures show a few samples of the sequence of pulses seen by the unit when the object passes along different paths. Each pulse of light through the mask produces a one. A pulse through the special hole produces a 0. The result is very repeatable and specific for 8 different directions:
11110 |
11110 |
01111 |
01111 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
110 |
110 |
10 |
10 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
1101 |
1101 |
1011 |
1011 |
This basic ability can be extended greatly with a finer hole mask, a
microcontroller to interpret the signals and a separate, second mask for the
second photocell with a different pattern. Expanded versions of the original
application could be produced with a pattern in the second mask something like
this:

The greater accuracy of this expanded system would be ideal for robot navigation in a house or office. Simply placing small (0.5 inch) mirrors on the ceiling every foot or so in a grid would allow a robot with nothing more than bumpers and a super bright LED pointed upward to actually navigate (rather than just bump about) through the space. Knowing how many mirrors there are between the walls of each room would make it possible for the 'bot to find itself when lost.
The mask pattern below is another example of a second mask. In this case the "eye" would be mounted on a pair of small servos and very simple rules would be applied to its movement. Each movement would continue until the hole mask caused one pulse on the first photocell. Alternating between up / down and left / right movements, the eye would move up or left when the second mask allowed the target to fall upon the second photocell and it would move down or right when no light penetrated the second mask.
If you have JavaScript enabled, you should be seeing a small red dot moving about in the mask.
Or you can go to http://www.sxlist.com/techref/new/letter/news0308.htm
Keep in mind that in this example, the dot represents a (relatively) stationary target and the mask is being moved to center on the target. On the web page, it is much easier to show the target as moving and the mask as stationary, but the opposite would be the case.
Notice that with only simple alternating movements based on the presence or absence of the image of the target through the mask, we are able to stay centered on the target most of the time.
|
|
Random movement in seconds.
|
You can left click on the squares in the table to turn the elements of the mask on or off and press SHOW to see / save the resulting HTML in the window to the right.
Hold down the shift key when you click to move the target to the location you want to test.
I don't think this design or the mask is perfect. "Simulation is doomed to succeed" so I bet the real thing will not work without changes. What is exciting about this is that a complete version could provide positional feedback:
| file: /Techref/new/letter/news0308.htm, 36KB, , updated: 2013/11/13 12:34, local time: 2025/10/31 10:18,
216.73.216.87,10-2-37-96:LOG IN
|
| ©2025 These pages are served without commercial sponsorship. (No popup ads, etc...).Bandwidth abuse increases hosting cost forcing sponsorship or shutdown. This server aggressively defends against automated copying for any reason including offline viewing, duplication, etc... Please respect this requirement and DO NOT RIP THIS SITE. Questions? <A HREF="http://www.piclist.com/techref/new/letter/news0308.htm"> August 2003 MassMind newsletter</A> |
| Did you find what you needed? |
|
o List host: MIT, Site host massmind.org, Top posters @none found - Page Editors: James Newton, David Cary, and YOU! * Roman Black of Black Robotics donates from sales of Linistep stepper controller kits. * Ashley Roll of Digital Nemesis donates from sales of RCL-1 RS232 to TTL converters. * Monthly Subscribers: Gregg Rew. on-going support is MOST appreciated! * Contributors: Richard Seriani, Sr. |
Welcome to www.piclist.com! |
.